This post is the second in a “mini-series” where I’ll document how I’m working with some different APIs for custom reporting in Power BI and Excel. Today’s post is about Harvest again, but only in general terms. The example is their time_entries endpoint but what I’m covering today I would term more generically as “iterating over a known number of pages” when calling an API.
There has been one post in the series so far:
In this post, I will describe the following items:
- When to use pagination techniques
- Updating the query to add a pagination technique
- Transforming the results into data
When to use pagination techniques
The short answer is “it depends”. My opinion is this: use queries with pagination techniques built in for anything where there is a chance of getting more than one page of results back. If I use Harvest for context here, time_entries for sure requires pagination, but clients may not (for me). I have 20 client records in that endpoint now, and a page limit of 100 records so I feel safe ignoring pagination on a “clients” endpoint for now, it will be years before I have 5x that many customers. At some point there is a tipping point for including pagination in the query, and the decision on where that falls is based on the underlying data being pulled in. Once a given list had 50 or 60 records in it, I would likely add pagination to that endpoint if I were pulling in the details to Power Query just so I don’t have to pay attention to when it “rolls over” to more than one page of records. It adds a relatively minimal overhead to the query.
What happens if I don’t paginate? Some day, when it gets to record #101, some data will simply be missing. I don’t know for sure if it’s record #1 or record #101 or somewhere in between but something will be missing. Depending on what is being pulled in, that may be a pivotal mistake in the query and honestly, it’s a bit hard to diagnose. Nothing will pop up to say “Hey, you’re missing some records in this query”.
I ran into this with another API where I had initially paginated incorrectly but didn’t realize it. In that case, it was a list of tasks, and I thought things were working as I was retrieving 2 pages of tasks (<200). However, as soon as I got to adding tasks 201, 202, and 203 to my project tracking, they weren’t appearing and it took a little while to realize it was a pagination issue. I will explain more about this when I get into my ClickUp example.
Updating the query from the last post
Here is the final query from the last post: the date-filtered query for time_entries in Harvest.
let
StartDate=Date.ToText(#date(Number.FromText(ReportYear),1,1)),
EndDate=Date.ToText(#date(Number.FromText(ReportYear),12,31)),
Source = Json.Document(Web.Contents(HarvestBaseURL,
[RelativePath="time_entries",
Query=[access_token=HarvestAccessToken,
account_id=HarvestAccountID,
from=StartDate,
to=EndDate]]))
in
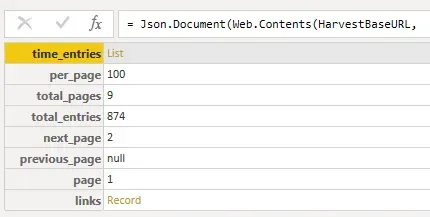
SourceHere as a reminder is what that query returned. In this case, what’s fantastic about this result is *that I already know* that there are 9 pages of results to page through. Trust me, that’s amazing and makes this pagination query so much simpler!
Here is a revised query to handle pagination, and below it I will walk through what elements have changed and why. I have below a screenshot that shows the line numbers, which are easier to reference in the explanation.
let
StartDate=Date.ToText(#date(Number.FromText(ReportYear),1,1)),
EndDate=Date.ToText(#date(Number.FromText(ReportYear),12,31)),
Source = Json.Document(Web.Contents(HarvestBaseURL,
[RelativePath="time_entries",
Query=[access_token=HarvestAccessToken,
account_id=HarvestAccountID,
from=StartDate,
to=EndDate]])),
Pages = {1..Source[total_pages]},
PageList = Table.FromList(Pages, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
GetTimePages = Table.AddColumn(PageList, "Custom", each Json.Document(Web.Contents(HarvestBaseURL,
[RelativePath="time_entries",
Query=[access_token=HarvestAccessToken,
account_id=HarvestAccountID,
from=StartDate,
to=EndDate,
page=Text.From([Column1]) & ""]])))
in
GetTimePages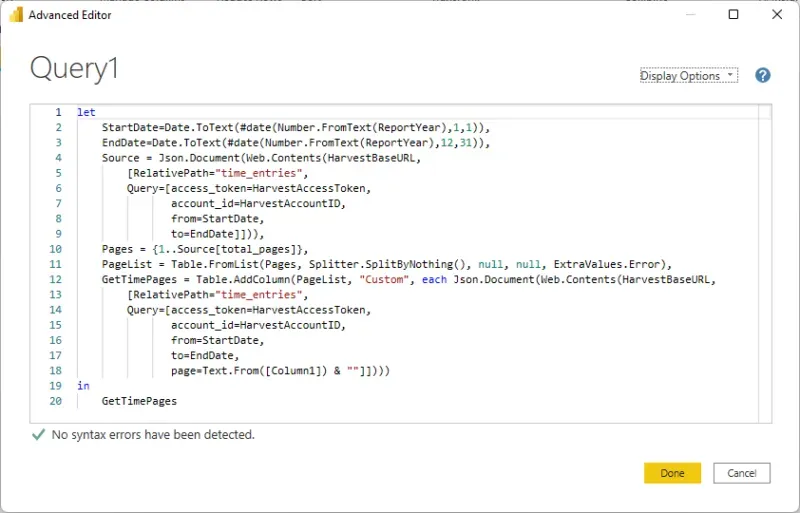
What the code does
Lines 1 through 9 are the same as before… no changes whatsoever. We are running the query once to determine how many pages of data there are. That’s it.
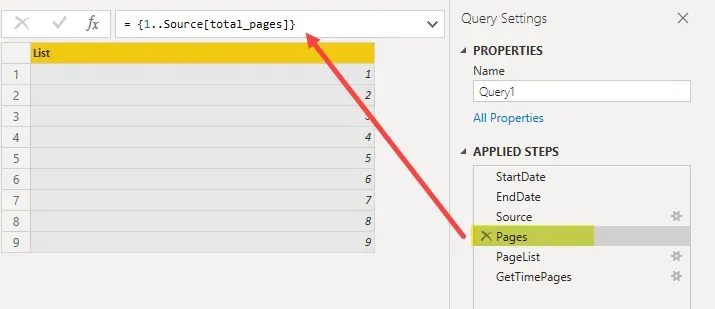
Line 10 sets an array from 1 to the “total_pages” value in the result of the initial query, or in my case, pages 1 to 9. I have 874-time entry records in 2021 to date, and by the time I get to next week, I may be on “page 10” but I don’t have to worry about that, the query is dynamic. What is important to note here is understanding what page numbers start at with the API. In Harvest’s case, they start at page 1. In ClickUp’s case, which I will be writing about next in this series, the first page of results is “page 0” so the range will be 0 to something.
If I go to that step in Applied Steps in Power Query, this is what I see: a list of pages, 1 to 9.
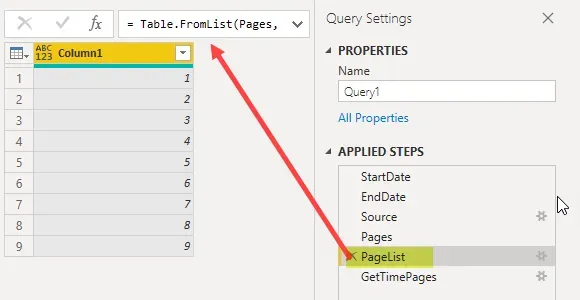
Line 11 is what I called “PageList”. Ultimately the step after this is to iterate through a “table” of numbers (pages), so this step is converting the “list” of pages to a “table” of pages. It seems meaningless but it’s not!
Line 12 (through 18) will look sort of familiar. At this point, we have our table of page numbers and now we need to start the “iteration” part: looping through each page to get the results from each page. This involves calling the query again, once per page. One slight difference to note is on line 18 of this section: a new Query for “page=” and the value from Column1 of the PageList table, which will be dynamic as it reads through the array of page numbers, 1 through 9.
The rest of the query is virtually the same with the same query date filters. At this point don’t change what filters are on the query, the filters should be the same as the original query except for the addition of the “page” filtering.
Why? If, for instance, one were to remove the date filters at this point, the original query without date filters had 45 pages of data; however, we have told PQ to loop through 9 pages of data, based on the filtered list of pages. It would, in theory, loop through 9 pages of the larger 45-page data set and I’d get seemingly random results back. It would ignore pages 10 through 45 and who knows what data I would get back!
The important part of this section is understanding that if I change the filtering on the initial results at all (lines 6 to 9), I need to repeat the changes on the second query section in lines 14 to 17. “Page” filtering will only ever be on the second query though.
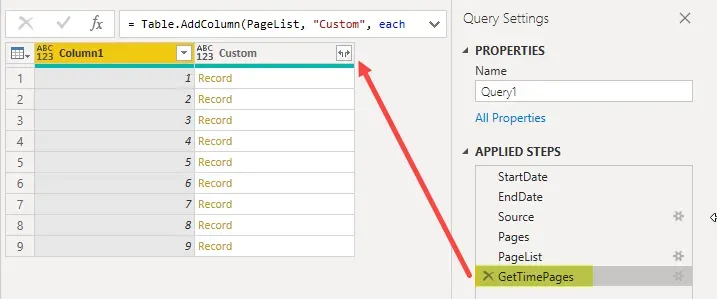
Now we are ready to start the transformation process and I have not pasted those steps of the query simply because I find it simpler at this stage to just start expanding the data via the user interface in Power Query.
Transforming the results into data
Let’s start with expanding the “Custom” column, right where the arrowhead is pointing in the screenshot above. There will be a prompt to select which columns to extract and in this case, I only want the one called “time_entries”.
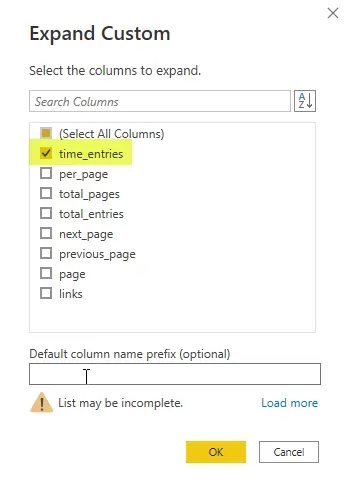
The result is a “List” per page/row of the table. Click on the “Expand” button on the “time_entries” column (not pictured in a screenshot), to expand the lists. Choose “expand to new rows” when given the choice. Each “list” is a set of 100 records, up until I get to page 9 of course, when the list contains <100 records. Expanding to new rows tells Power Query to “get all the rows of data”, essentially.
Now the result is a table of “records” instead of “lists”. I now see in the footer “2 columns, 874 rows” which is exactly what I am expecting based on our original initial query before we started this pagination exercise!
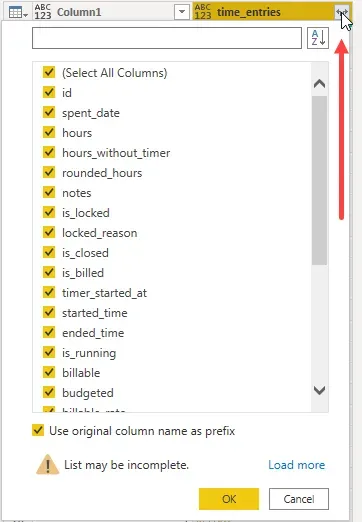
Click on the “Expand” button on the “time_entries” column one more time to expand those records into columns of data. Each one of those records is a single timesheet entry, in this case with date, project, hours, rate etc. as I would expect to see on a timesheet.
Further transformation
At this point, I will not go through the subsequent transformation steps in detail, but after doing what I describe above, I am at a step that looks like this screenshot below: a column selection window. The columns in the selection window are the columns described in the time_entries API documentation. I can start selecting or deselecting as I need and get into further transformation steps as I see fit.
Summary
While this might have seemed a little convoluted if this is new (trying pagination), trust me when I say this was a relatively easy example! In the next part of the series I will be digging into ClickUp and while I love the product, the APIs are not as friendly to work through as they do not tell me how many records I have to page through.
After writing the blog about the equivalent topics with ClickUp, I wrote “Part 5” of the series which is scheduled after the 2 next parts of this series. In that 5th post, I will revisit this API using List.Generate instead of the technique above. Overall, I think it’s a more streamlined method to get the same result. Stay tuned for that!